
Every enterprise technology vendor declared 2025 the year AI agents would go mainstream. Salesforce closed 18,000 Agentforce deals (Agentforce is their AI-powered platform for building and managing autonomous agents). Microsoft repositioned its entire Copilot strategy around autonomous agents. Gartner even named agentic AI a top 10 strategic technology trend.
And yet, when McKinsey surveyed enterprise leaders at the end of 2025, the numbers told a different story. Though 62% of organizations were experimenting with AI agents, fewer than 25% had successfully scaled them into production. And those numbers are the promising ones. After analyzing over 300 enterprise AI initiatives, the MIT NANDA initiative found that 95% of generative AI pilots delivered zero measurable return on investment.
Contrary to popular belief, the problem was never technology. The models got smarter and the frameworks matured as the investment continued to pour in. The problem was that most organizations treated agentic AI as an upgrade to their existing automation stack rather than a fundamentally different operating model.
They bolted agents onto legacy processes instead of redesigning workflows around what agents can actually do. They optimized for demos instead of production. And they measured success with infrastructure metrics that told them nothing about whether the AI was actually creating business value.
This definitive guide exists to close that gap. It provides a practitioner's framework for understanding what agentic AI actually is, where it creates real value, how to evaluate agent performance in production, and what separates organizations that scale from organizations that stay stuck in pilot purgatory.
The term "agentic AI" gets thrown around loosely enough that it's worth establishing what it actually means (and more importantly, what it doesn't mean). Agentic AI refers to autonomous systems that can pursue goals across multiple steps, reason about context, take actions across different systems, and verify their own outputs.
That description sounds simple, but the distinction from prior generations of automation is significant. Traditional rule-based automation follows scripts. If the input matched the expected pattern, the script executed. If it didn't, the script broke. Robotic process automation, or RPA, improved on this by mimicking human interactions with software interfaces, but it still operated on rigid rules that couldn't handle variability. Then in recent years, conversational AI and copilots added intelligence to the interface layer, but they still required a human to make decisions and take action.
Agentic AI operates differently. An agent receives a goal, not a script. It plans the steps required to achieve that goal. It reasons about which tools to use, which systems to query, and which actions to take. It executes those actions, evaluates the results, and adjusts its approach if something unexpected happens. And critically, it can do all of this across multiple systems, documents, and data sources in a single workflow.

Context is mentioned constantly in enterprise AI conversations, but rarely with enough precision. Saying an agent “needs context” is like saying a building needs a foundation. True, but useless unless you specify what the foundation actually does. Agents need context for five distinct reasons, and each one maps to a different failure mode when it’s missing.
1. To encode business logic. An agent without encoded business logic is a general-purpose language model with system access. It can process information, but it doesn’t know your rules, your escalation paths, your approval thresholds, or your compliance boundaries. Context is the mechanism that transforms a generic capability into something that operates the way your organization actually operates. When a claims agent knows that water damage claims over $50,000 require a field adjuster and under $10,000 can be auto-approved, that’s not a prompt. That’s encoded business logic carried as context.
2. To preserve stateful continuity. Agents that lose state between steps aren’t autonomous. They’re stateless functions being called in sequence. Real workflows involve multi-step processes where a decision at step three depends on what happened at step one. A KYC agent that re-verifies identity documents from scratch every time it moves to the next check isn’t efficient. It’s broken. Stateful continuity means the agent carries forward what it has already learned, what it has already validated, and what decisions are still pending, so every subsequent step builds on prior work instead of repeating it.
3. To enable governance and auditability. In regulated industries, the question is never just “what did the agent do?” It’s “what was the agent authorized to do, what information did it use, and can you prove it?” Context must carry permissions, data lineage, and access controls as critical properties, not as afterthoughts. When a compliance officer asks why an agent approved a transaction, the answer needs to trace back through the specific policies applied, the data sources consulted, and the confidence thresholds that were met. Context that doesn’t carry its own provenance is context that can’t be audited.
4. To create deterministic behavior. Large language models are probabilistic by design. Given the same input twice, they can produce different outputs. That’s a feature for creative applications and a liability for enterprise operations. Context is the infrastructure layer that constrains probabilistic outputs into deterministic behavior. When an agent operates within specific rules, specific thresholds, specific escalation criteria, the underlying model’s variability gets channeled into consistent, repeatable decisions. Without this constraint layer, you get an agent that handles the same loan application differently on Tuesday than it did on Monday, which is the fastest way to lose both regulatory standing and organizational trust.
5. To scale across agents and workflows. A single agent operating in isolation can get by with local context. But enterprise deployments don’t stay isolated for long. The claims agent needs to share information with the fraud detection agent. The onboarding agent needs to hand off to the provisioning agent. The compliance agent needs visibility into what every other agent did and why. If context is locked inside individual agents, every new workflow starts from zero, every handoff loses information, and the organization never achieves the compounding returns that justify the investment. Context must be shared, portable, and unified across the agent ecosystem, not siloed within individual workflows.
These five requirements explain why context isn’t a feature you can bolt on after deployment. It’s the architectural foundation that determines whether agents produce generic outputs or business-specific outcomes. Organizations that treat context as a prompt engineering problem will keep building agents that work in demos and fail in production. Organizations that treat context as infrastructure will build agents that compound in value with every deployment.
The case for agentic AI becomes clear when you look at where script-based and task-level automation consistently breaks down. S&P Global Market Intelligence reported that 42% of companies abandoned most of their AI initiatives in 2025, up from 17% in 2024. And the reasons behind these failures are remarkably consistent across industries and company sizes.
Most notably, real-world operations don't follow clean patterns. And unfortunately, variability overwhelms rigid workflows. Documents arrive in inconsistent formats, regulatory requirements can change mid-quarter, etc. Which means every exception requires a human to step in, evaluate, and decide. This translates to automation that only works for the simplest version of the process it was designed to handle.
Next is the reality that core systems change faster than integrations can keep up. Enterprise environments run dozens of interconnected platforms. ERPs, CRMs, document management systems, compliance databases, and legacy portals that no one wants to touch but everyone depends on. Traditional automation creates brittle connections between these systems that break whenever one of them updates an API, changes a data format, or adds a new field.
Then you have opaque decision-making blocks legal, audit, and enterprise rollout. For any automation that touches regulated processes, someone needs to explain why a decision was made. Script-based systems can log what happened but can't explain why. And when regulators or internal audit teams can't trace the reasoning behind a decision, the automation gets confined to low-risk, low-value tasks where nobody asks hard questions.
As if those weren’t enough, traditional automation carries a high cost with no compounding returns. Traditional automation projects are expensive to build, expensive to maintain, and every new workflow starts from scratch. There's no knowledge reuse, no shared context, no architectural advantage that makes the tenth automation faster or cheaper than the first.
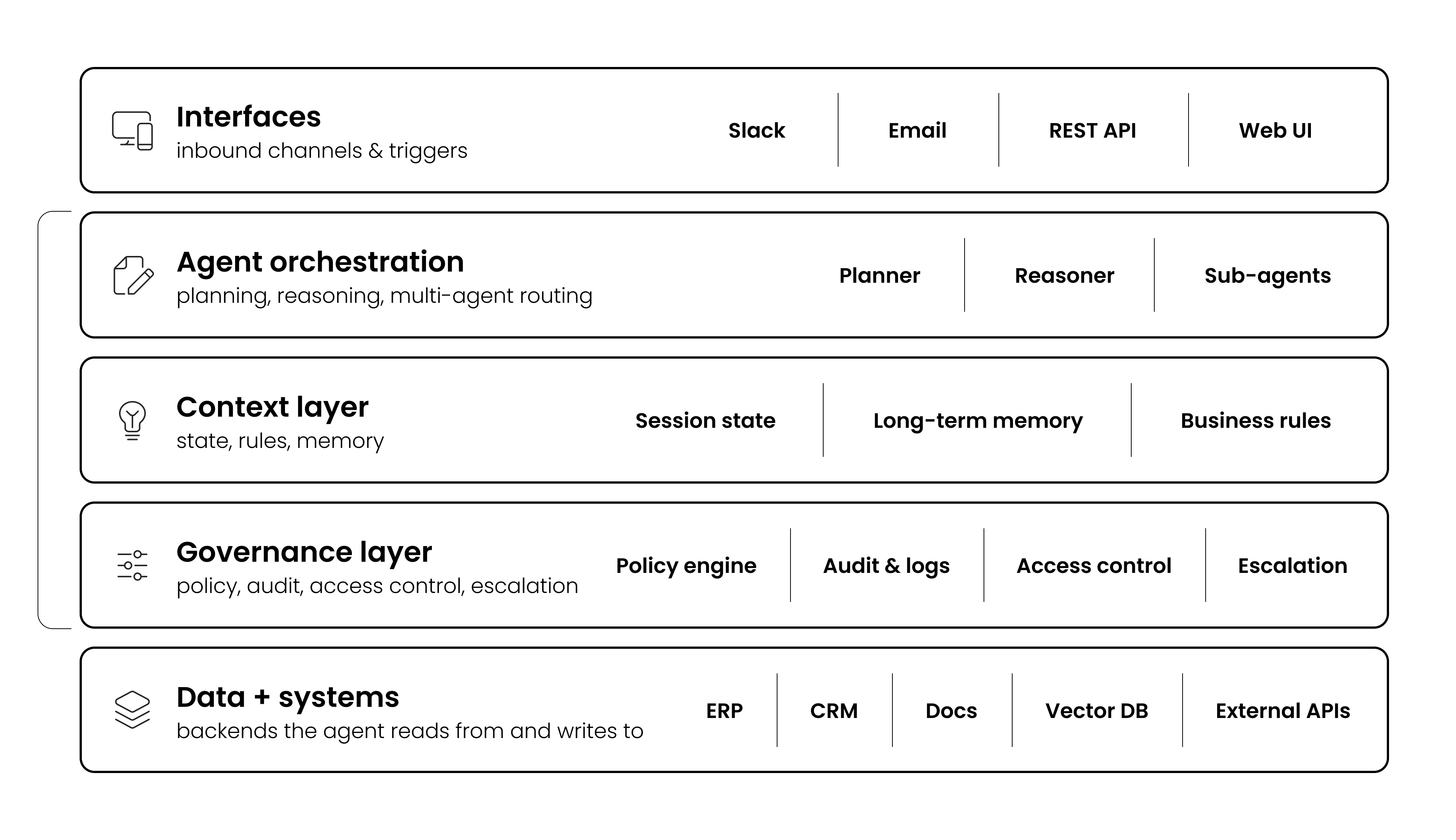
The gap between a working pilot and a production system is not primarily technical. It's architectural, operational, and organizational. The MIT study found that large enterprises take an average of nine months to scale from pilot to production, compared to 90 days for mid-market firms. But why?
The difference isn't resources or technology. It's that larger organizations have more complex integration requirements, more stakeholders who need to approve decisions, and more legacy systems that weren't designed for autonomous interaction. Production readiness requires more capabilities working together (actually four to be exact):
Secure connectivity. Agents need to link to your systems, documents, and portals without creating new security vulnerabilities. This means data stays within your environment, access controls are enforced at the agent level, and connections to legacy and non-API systems are handled through governed interfaces rather than workarounds.
Encoded business knowledge. An agent that doesn't know your rules, policies, and operational logic is just a generic language model with system access. The agent should perform context-aware reasoning grounded in your data. Encoding business knowledge means capturing not just the documented policies but the operational reality of how decisions actually get made, which exceptions are routine, and which require genuine escalation.
Governed execution. Every action an agent takes in production must be deterministic, auditable, and reversible. This means full execution lineage (what the agent did, why it did it, and what data it used), confidence scoring on every decision, and human approvals that trigger automatically when uncertainty exceeds defined thresholds.
Persistent operational state. Production agents do not operate as stateless conversations. Every workflow instance maintains a structured operational state that serves as the system of record for that process. Without structured state, agents produce responses. With structured state, they execute operations.
State-based risk escalation. Risk management in production environments must be tied to workflow state, not just model confidence. Different stages of a workflow carry different regulatory and operational risk, and certain state transitions should automatically trigger mandatory approvals, policy validations, or escalation logic. This state-based risk segmentation allows organizations to expand autonomy safely over time while maintaining structured governance and oversight.
Continuous learning. A production agent that doesn't improve over time is a depreciating asset. The system needs feedback loops that capture corrections, outcomes, and human judgments, and apply them systematically to improve future performance. This isn't the same as model retraining. It's operational learning. The agent gets better at your specific workflows, with your specific data, for your specific edge cases.
Not every workflow benefits equally from agentic AI. The highest returns come from processes that combine high volume, significant variability, multi-system orchestration, and decision-making that requires judgment rather than just pattern matching. Let’s take a look at some of the most prevalent initiatives.
Loan and credit applications are a natural starting point. A traditional process involves a human reviewing an application, checking it against lending criteria, requesting missing documentation, and either approving it or preparing a file for underwriting review. An agentic system reviews the application, validates against policy, identifies gaps, requests missing documents from the applicant, and routes the complete file for human review only when the decision falls outside its confidence threshold. What previously took days collapses to hours, with fewer errors and a complete audit trail.
Insurance claims processing follows a similar pattern. Millions of claims flow through insurance companies annually, and traditional systems require human involvement at nearly every step. An agent can verify claims against policy terms, assess coverage, cross-reference fraud indicators, approve or deny based on clear criteria, and initiate payment when appropriate. The complexity that makes this unsuitable for simple automation, is exactly what agentic AI handles well because it reasons about context rather than following rules.
Financial compliance workflows, particularly KYC and AML processes, represent one of the highest-value applications. Customer due diligence involves pulling information from multiple sources, assessing risk against regulatory criteria, flagging suspicious patterns, and generating documentation that regulators can audit. These workflows are currently labor-intensive, error-prone, and increasingly difficult to staff. Agentic systems can execute the end-to-end process while maintaining the audit trail and reasoning transparency that regulators require.

Document processing and data extraction at enterprise scale involves more than OCR and keyword matching. When an organization receives thousands of contracts, invoices, disclosures, or policy documents, the real work is extracting relevant information, validating it against existing records, flagging inconsistencies, and loading clean data into downstream systems. An agent handles this as a continuous workflow (ingest, extract, validate, reconcile, and load, with exceptions routed to humans only when confidence is low).
Customer service triage and escalation offers immediate, measurable ROI. Not every customer inquiry needs a human immediately. An agent can handle first-contact resolution for the majority of standard requests. Things like answering questions from knowledge bases, providing account information, processing routine changes, and qualifying issues for escalation. The key distinction from traditional chatbots is that an agentic system can actually resolve the issue, not just direct the customer to a different channel.
Implementing an AI agent is the beginning of a continuous optimization process, not a deployment milestone you can mark as complete. The evaluation framework matters because AI agents fail differently than traditional software, and conventional monitoring is insufficient to detect the failures that actually impact business outcomes.
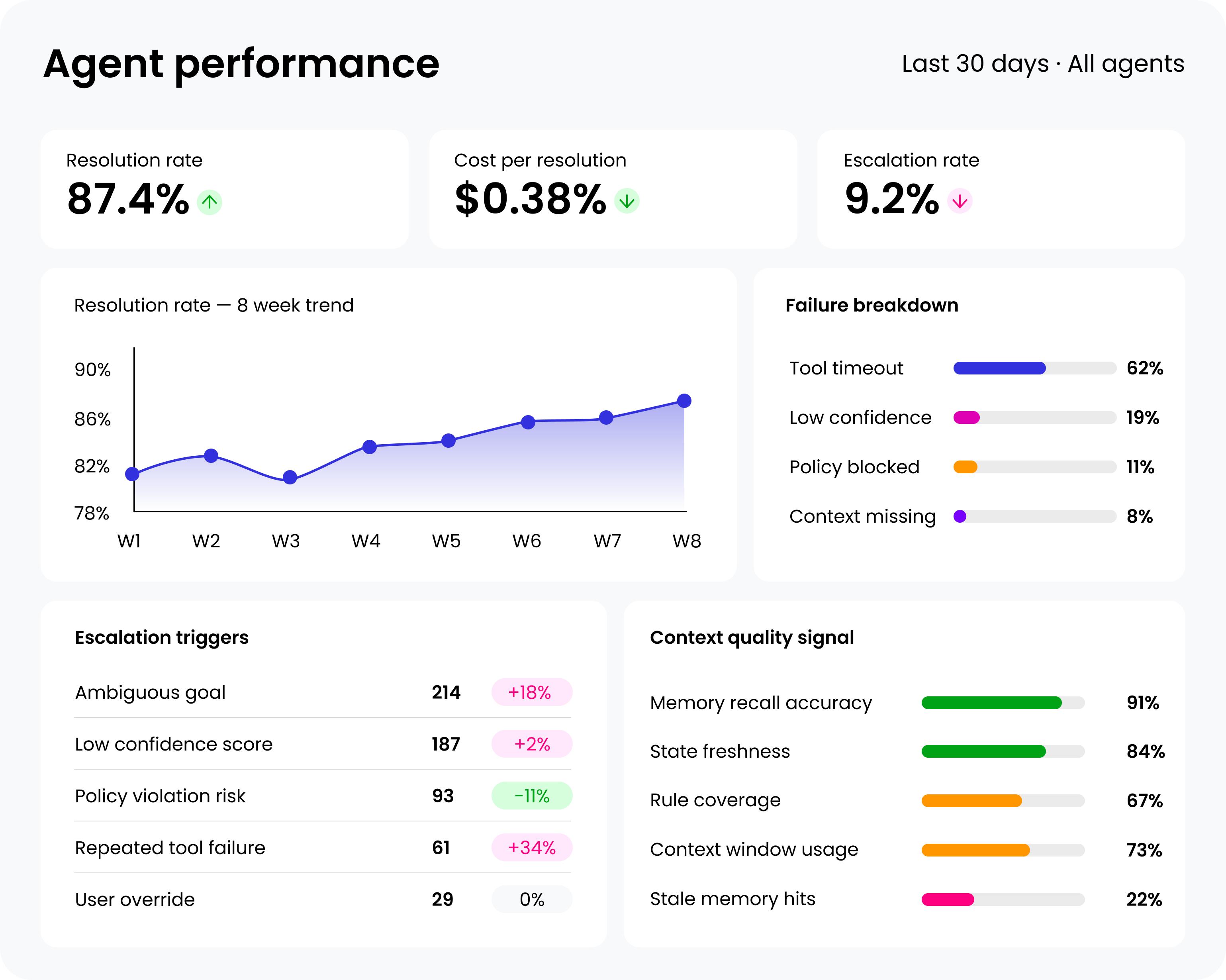
Traditional IT monitoring tracks uptime, latency, error rates, and throughput. An AI agent can score perfectly on every one of these metrics and still provide incorrect, irrelevant, or harmful outputs. This disconnect between technical metrics and business outcomes is where most organizations lose visibility, and where problems compound quietly until someone notices the downstream impact. A complete evaluation includes the following five interconnected metrics that link agent behavior directly to business objectives:
1. True AI resolution rate measures the percentage of end-to-end tasks an agent completes successfully without requiring human intervention. This is not the same as response rate, interaction rate, or the number of queries answered. A resolution means a completed business outcome (a confirmed appointment, a closed support ticket, a qualified lead entered into a CRM, or a claim processed to completion).
2. Cost per resolution calculates the total operational cost of the AI agent divided by the number of successful task completions. This is deliberately different from cost per interaction, which can be misleading. The calculation needs to include all operational costs (infrastructure, software licensing, development, ongoing maintenance, and the cost of human oversight). This provides a direct ROI comparison between the AI agent and the fully loaded cost of a human completing the same task.
3. Failure analysis categorizes unsuccessful interactions by root cause to create an actionable improvement roadmap. Simply tracking a failure rate tells you almost nothing useful. Understanding why failures occur is what drives targeted improvement. The most common failure categories are:
4. Human escalation analysis identifies the specific conversational points and topics that cause users to abandon the AI agent for human support. Each escalation is a diagnostic data point that reveals the precise boundaries of an agent's capabilities. The analysis should focus on contextual findings like what topic triggered the escalation, what was the agent's last response, or if there are patterns across user segments or time periods.
5. Shared context quality is the metric most directly determines whether an agent produces outputs or outcomes. Shared context is the combination of:
Context determines relevance, prioritization, and trust. Without shared context, an agent can produce technically correct responses that miss the point entirely. Evaluating context quality means analyzing whether agent decisions align with human judgment, business priorities, and real-world outcomes, not just technical correctness.
Moving from understanding these metrics to actually implementing them requires some fundamental steps that are simply unavoidable. Obviously defining success for each use case before deployment should be your first move.
Your team should establish a clear, measurable definition of what constitutes a successful resolution for every task an agent handles. This becomes the primary benchmark for the resolution rate metric. If you can't define success precisely, you're not ready to deploy.
For example:
Treat observability as a deployment prerequisite, not a post-launch enhancement. Meaningful metrics are impossible without comprehensive data collection. The agent needs to log all critical events (task initiation, intent recognition, API calls, decision points, failure modes, and escalation triggers). This isn't optional logging that you add later. It's a core architectural requirement that determines whether you can evaluate, debug, and improve the system in production.
From there, establish baselines and a regular review cadence. After collecting initial data, set performance baselines for all five core metrics. Schedule regular review cycles, weekly or bi-weekly, to analyze trends and measure the impact of changes. This transforms evaluation from a periodic audit into a continuous optimization process.
The organizations that treat agent performance as a living metric, adjusting thresholds, expanding capabilities, and feeding learnings back into the system, are the ones that successfully scale from one workflow to many.
As with everything technology related, there are a couple implementation considerations that deserve emphasis. First, audit logging is a non-negotiable prerequisite. Without structured, comprehensive logs, root cause analysis is impossible, regulatory compliance is unprovable, and continuous improvement is guesswork.
Second, effective evaluation requires cross-functional collaboration. Business stakeholders define what success looks like. Product managers prioritize which improvements to make. Engineers implement the changes. And governance teams ensure that context is versioned, auditable, and aligned with business reality. No single team can do this alone.
As you can see, the vendor landscape for agentic AI is crowded and confusing. Much of which is the result of over-promising and under delivering.
Gartner has warned explicitly about "agent washing," where vendors rebrand existing products (chatbots, RPA, traditional automation) as agentic without adding genuine autonomous capabilities. One of their polls from 2025 found that while 61% of organizations had invested in agentic AI, many were buying rebranded products that couldn't deliver on the promise.
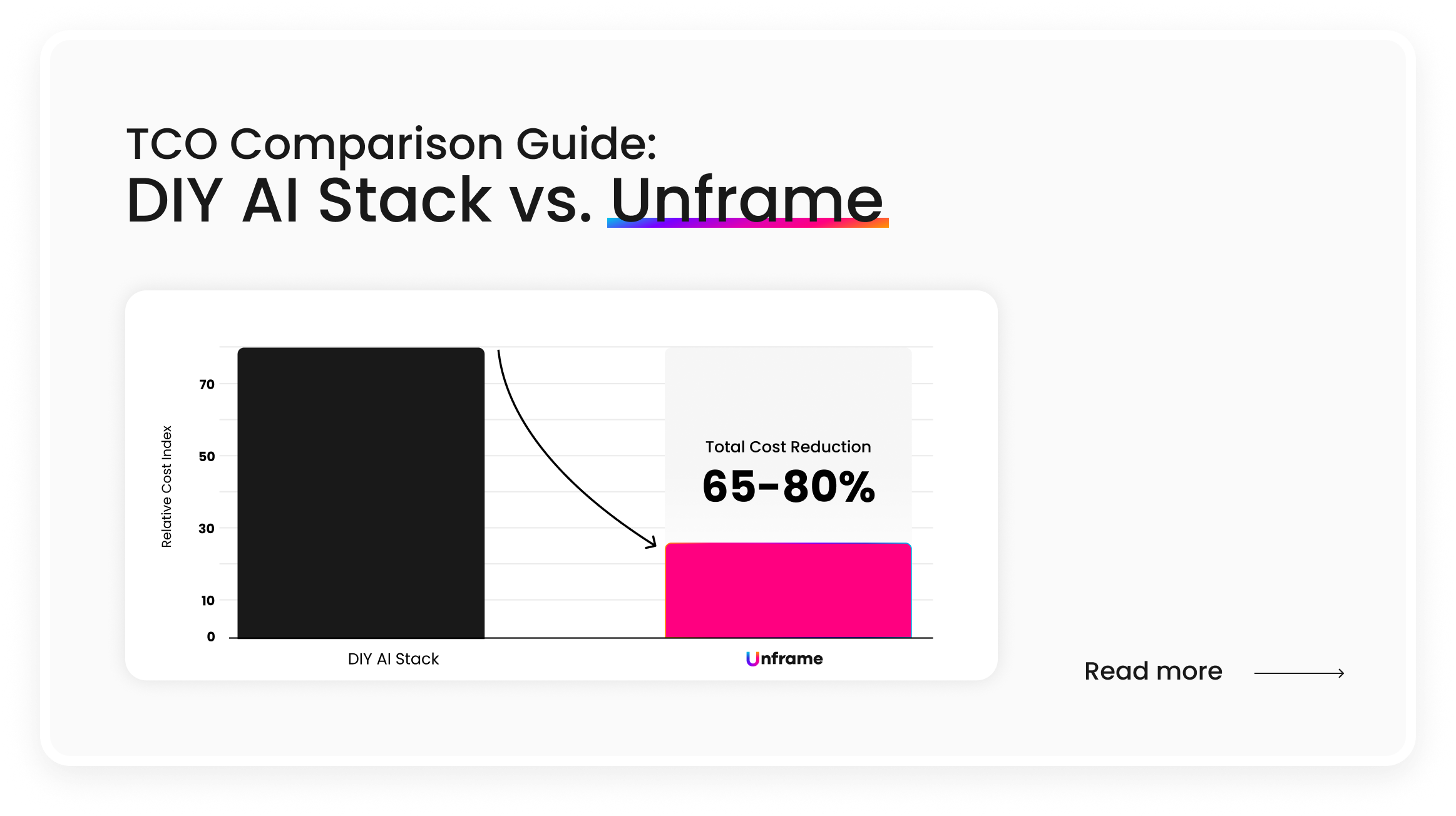
Based on everything we recommended above, you definitely shouldn’t fall in this bucket. But let’s say you encounter a vendor that checks the right boxes. You also need to look at deployment timelines realistically. If a vendor tells you production deployment takes six to twelve months, they're describing a consulting engagement, not a platform.
The managed AI delivery platforms that have gained traction in the enterprise market are delivering production-ready agents in days or weeks, not quarters, because they're assembling proven components into tailored configurations rather than building custom solutions from scratch.
Not all agentic AI platforms are built the same. In practice, enterprise buyers encounter three common approaches:
These provide toolkits, frameworks, and orchestration layers that require significant internal engineering expertise. While flexible, they often shift integration complexity, governance design, and production hardening onto the customer. Time-to-value depends heavily on internal resources.
Some vendors approach agentic AI as a bespoke systems integration project. Custom agents are designed from scratch for each workflow. These engagements can take six to twelve months and require ongoing services to maintain. The result is often powerful — but expensive, slow to scale, and difficult to replicate across additional workflows.
Others repackage chatbots, RPA, or LLM wrappers as “agents.” These systems assist users but do not own end-to-end outcomes. They rely heavily on human supervision and struggle in regulated or high-variability environments.
A newer model has emerged: managed AI delivery platforms. These platforms assemble proven architectural components, secure connectivity, encoded business logic, governed execution, persistent state, and observability - into tailored, production-ready agents delivered in weeks rather than quarters.
Organizations that will successfully scale agentic AI in 2026 and beyond are the ones that treat it as an operating model transformation, not a technology procurement. They start with one high-value workflow, prove it works in production with real data and real users, measure outcomes with the right metrics, and expand methodically. The technology is ready. The question is whether your organization is ready to use it.
To learn how Unframe empowers customers with agentic AI for enterprise workflow automation, contact us.






.svg)