
Most enterprise AI projects die in data preparation. Why? Well believe it or not, it’s because the popular approach to making data "AI-ready" is fundamentally misaligned with how production AI actually works. As evidence, a Gartner survey of data management leaders found that 63% of organizations either do not have or are unsure whether they have the right data management practices for AI. The same research predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data.
The reality is, enterprises have spent decades optimizing data architectures for reporting. Those architectures were never built to support systems that need to learn, reason, and act autonomously. When organizations try to force AI workloads onto reporting infrastructure, it results in months of data preparation that goes stale within weeks, centralization projects that never finish, and governance models that either block AI adoption entirely or create security vulnerabilities at scale.
Informatica's CDO Insights 2025 survey confirms the pattern, identifying data quality and readiness as the primary obstacle to AI success at 43%. Also tied at number one is lack of technical maturity, followed by shortage of skills at 35%.
Taking all of that into account, we developed this guide to provide practitioners with a framework for AI data management that works in production. We’ll cover what it actually requires, why the conventional "clean it first, use it later" approach fails, and how to build data foundations that serve AI at the moment of decision rather than the moment of export.
The data preparation trap
The conventional approach to preparing data for AI follows a familiar playbook. Consolidate everything into a centralized repository. Clean it. Normalize it. Build a golden record. Then hand it to the AI team. The problem is that this foundation takes months to build, goes stale within weeks, and still fails to capture the business semantics that AI needs to reason effectively. Teams that have tried this approach know the cycle intimately.
This isn’t an execution failure. It’s a structural problem with treating data management as a prerequisite centralized project rather than a continuous capability. Enterprise data isn’t static. Schemas evolve. New systems get deployed. Business rules change. Customer records get updated across dozens of applications simultaneously. A data foundation built as a one-time centralization effort starts decaying the moment it launches. Yet organizations continue investing months of engineering effort in exactly this approach, because the reporting-era mental model says data must be unified before it can be useful.
And the proof is in the pudding. S&P Global's 2025 survey of over 1,000 enterprises found that 42% of companies abandoned most of their AI initiatives in 2025, up from 17% the prior year. Coupled with the RAND Corporation's analysis that over 80% of AI projects fail, twice the failure rate of non-AI technology projects. Obviously data preparation isn’t the only factor, but it’s the most consistent one.
What AI data management actually requires
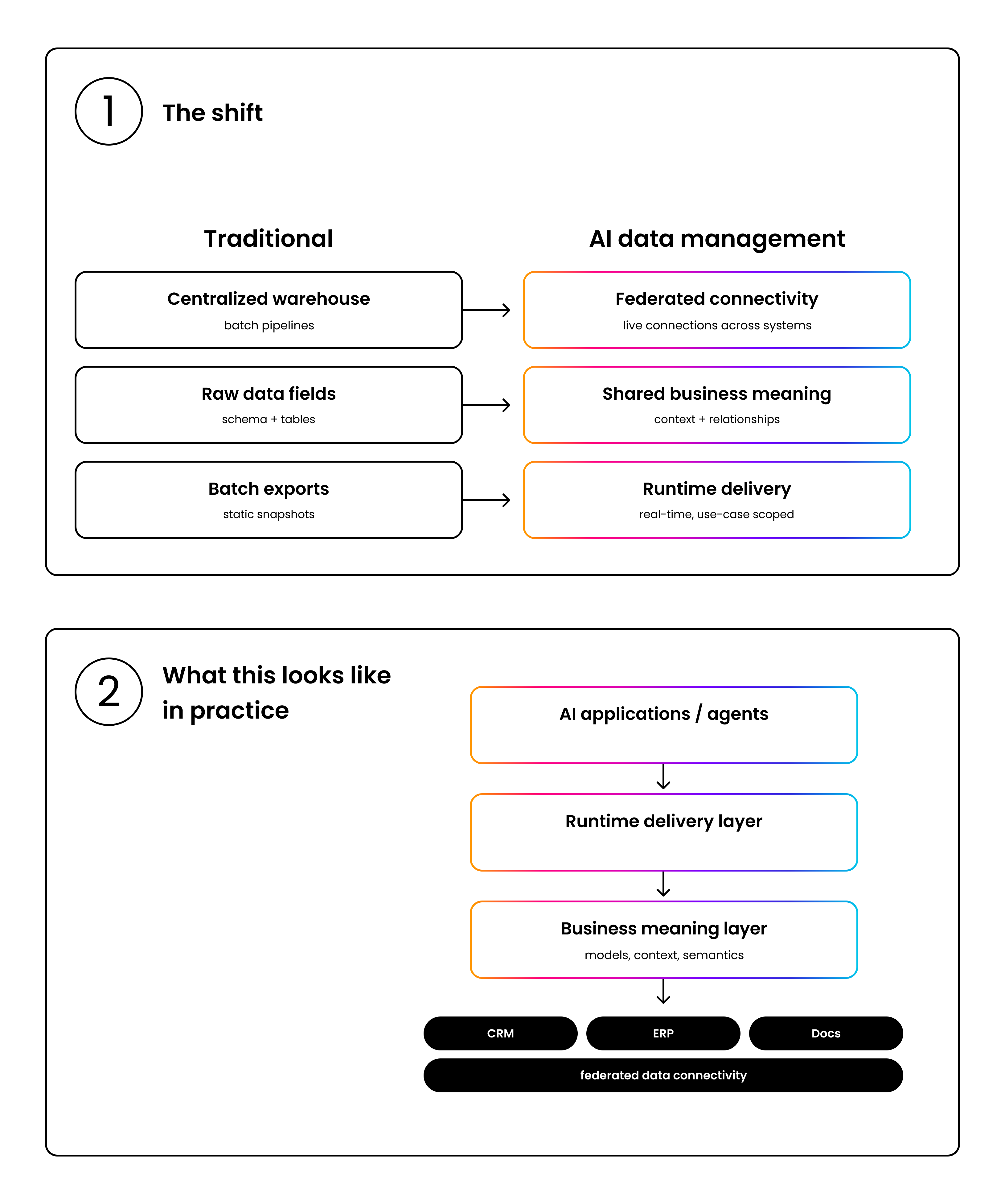
AI data management is fundamentally different from traditional data management, and the difference matters more than most organizations realize. Traditional data management optimizes for humans querying structured repositories. AI data management must optimize for systems that reason across fragmented data in real time.
To that point, there are three requirements that define the gap. First, AI needs federated connectivity across fragmented systems, not centralized data in a single warehouse. Enterprise data lives in dozens of systems that were never designed to work together: CRMs, ERPs, document repositories, compliance databases, legacy portals. The conventional response of consolidating everything into a data lake creates a new bottleneck without solving the underlying fragmentation. What production AI requires is a connected data layer that spans existing systems without requiring migration or consolidation, maintaining live links to data wherever it already lives.
Second, AI needs shared business meaning, not raw data. Connectivity solves the access problem but not the interpretation problem. A customer record pulled from a CRM tells the AI system a name and an account number. It doesn't tell the system how that customer's relationship works, what terms apply, what exceptions have been granted, or how that account relates to other entities across the business. The real challenge in AI data management is defining per-use-case data models that organize those fragments into structures AI can reason over consistently. This is how data extraction and abstraction capabilities transform raw inputs into usable intelligence.
Lastly, AI needs runtime delivery, not batch exports. AI systems need fresh, relevant data at the moment of decision, not batch exports that were current when they were generated but stale by the time they are consumed. When an agent needs to answer a question, or when an automation needs to make a decision, the data foundation must deliver exactly the view required for that specific request, scoped to the use case and filtered by the permissions model.
Why data centralization fails AI
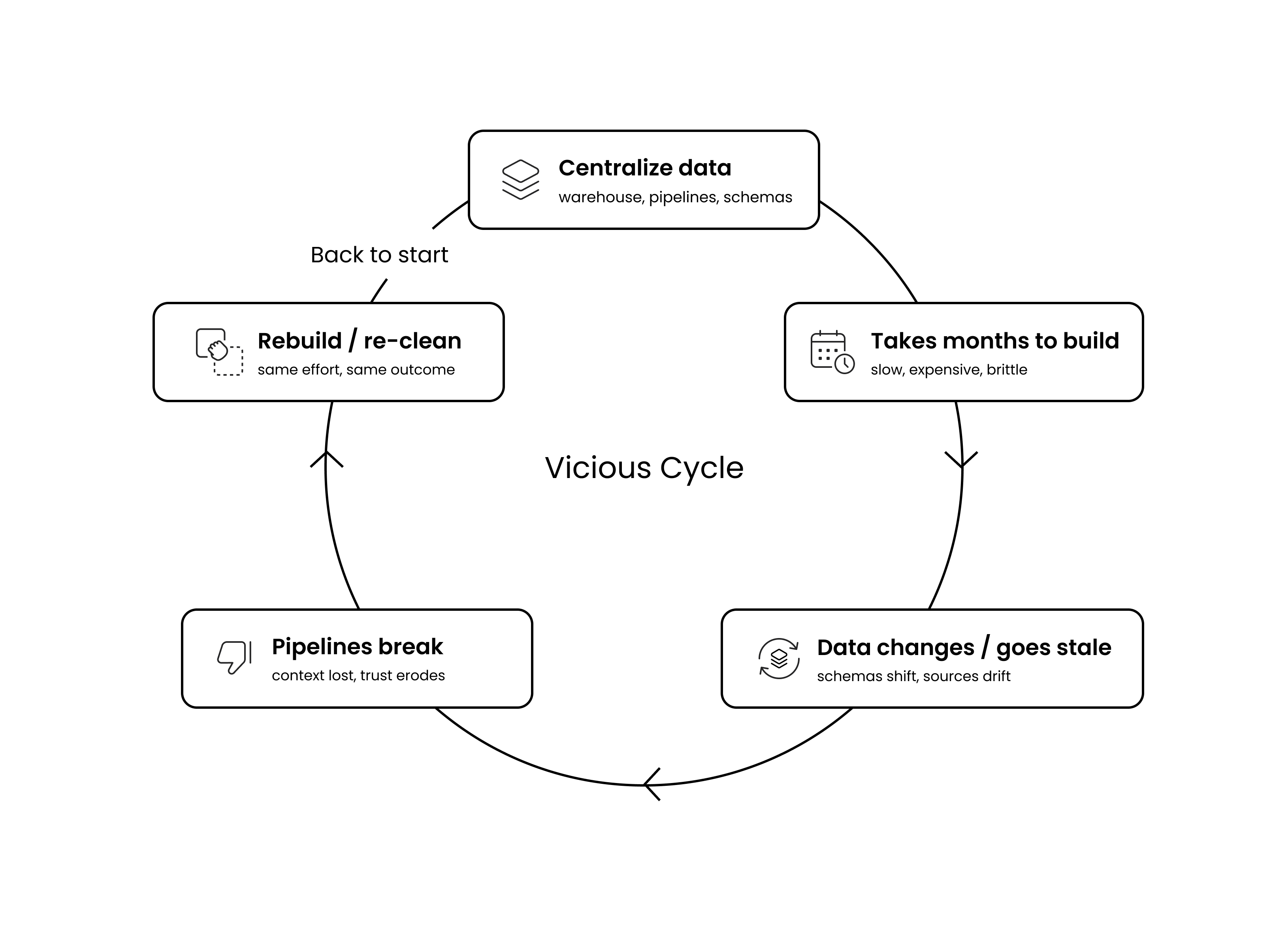
The instinct to centralize data before deploying AI is understandable. It worked for business intelligence. It worked for reporting. It even worked for early analytics workloads. But centralization as a prerequisite for AI introduces three problems that compound as AI adoption scales.
The first thing to think about is time to value. Centralization projects take months or years to deliver initial results. Meanwhile, AI use cases with clear business value sit in a backlog waiting for the data foundation to be "ready." By the time the foundation is built, the business requirements have shifted, the source systems have changed, and the competitive window may have closed.
McKinsey's 2025 AI survey found that organizations reporting significant financial returns from AI are twice as likely to have redesigned end-to-end workflows before selecting modeling techniques. The organizations that succeed are the ones that find ways to deliver AI value while building the foundation, not the ones that perfect the foundation before starting.
After building it, you also have to consider the maintenance burden. Every centralized data store requires ongoing synchronization with source systems. As the number of sources grows, the maintenance cost grows with it. Schema changes in upstream systems break pipelines. Data quality issues that were invisible in the source system become critical failures in the centralized store. The Dataversity 2024 Trends survey found that 68% of respondents cited data silos as their top data management concern, up 7% from the prior year. Centralization was supposed to solve silos. Instead, it often creates a new silo that is marginally better connected but exponentially harder to maintain.
And as if those weren’t enough to worry about, there’s also governance complexity. When data is copied from source systems into a centralized repository, the permissions model from the source systems does not automatically follow. An employee who should have access to certain records in the CRM may suddenly have access to those same records plus thousands of others in the data lake. In regulated industries like financial services, healthcare, and insurance, this permission drift creates compliance exposure that scales with every new dataset added to the centralized store. AI data security is not a feature you add after deployment. It’s a structural requirement that must be embedded in the data foundation from the start.
The adaptive data model
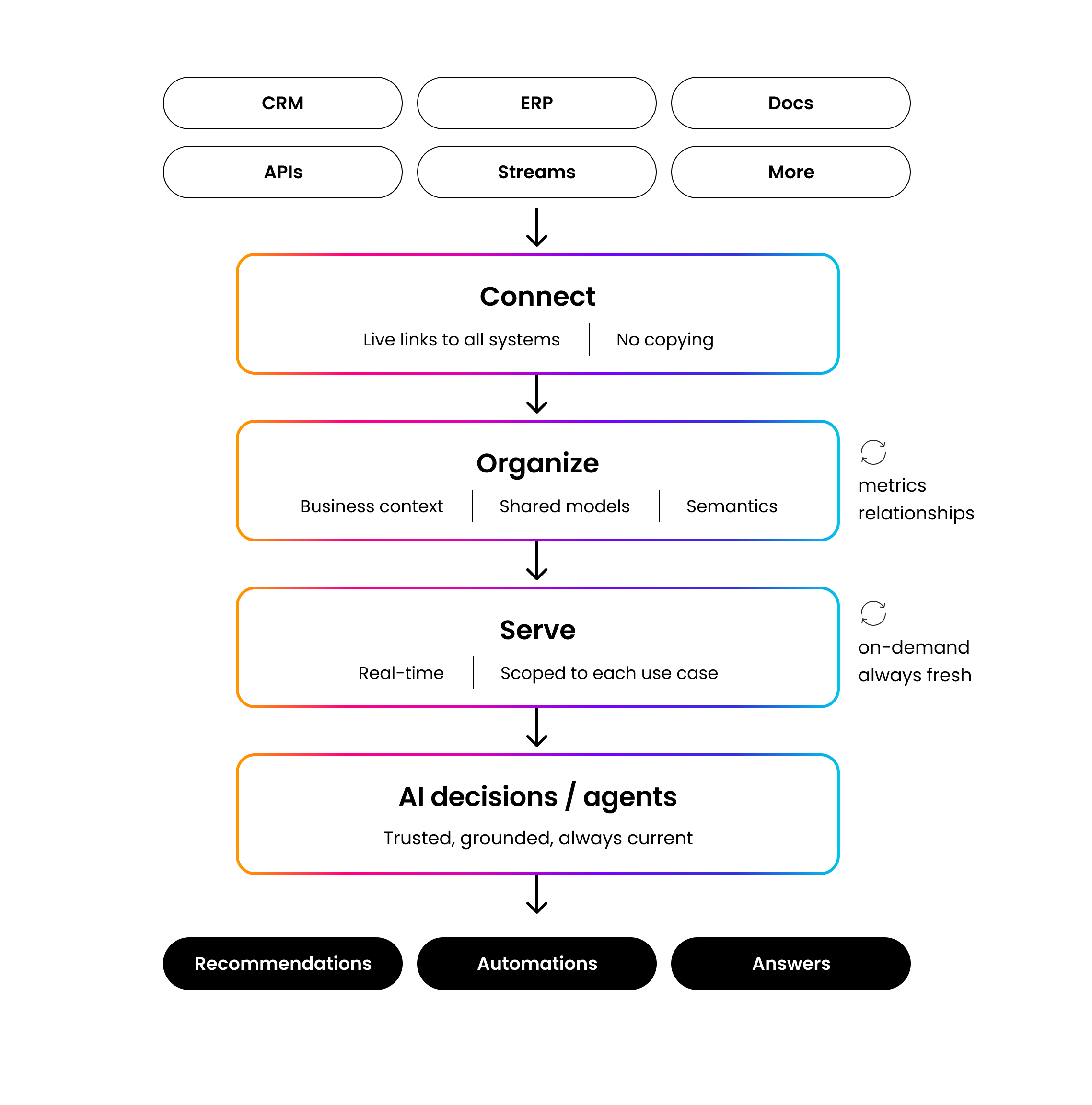
The alternative to centralization is what practitioners increasingly call an adaptive data model. It’s essentially a data foundation that resolves fragmentation, preserves shared semantics, and evolves as systems change.
An adaptive data model operates on three principles.
- Connect: continuously link to data across the enterprise environment without centralizing or replacing existing systems.
- Organize: build data models per-use-case that preserve business semantics, enabling AI to reason consistently about what terms mean in a specific operational context.
- Serve: deliver real-time, use-case-specific views for each AI application at the moment of decision.
This approach changes the economics of AI data management entirely. Instead of spending months building a centralized foundation before the first AI use case can go live, organizations can connect to existing data sources, organize context for a specific use case, and serve that context to production AI in days rather than quarters. Each subsequent use case builds on the same connected data layer, creating compounding returns where every deployment makes the next one faster.
The adaptive model also solves the governance challenge that centralization creates. When data is accessed in place rather than copied to a centralized store, the permissions model from the source system can be inherited directly. Access controls that have already been defined in databases, document repositories, and SaaS applications automatically apply to AI. This permission-aware approach means AI can scale safely across the organization without requiring a parallel governance infrastructure that must be maintained separately from the source systems it protects.
For organizations that have already invested in centralized data infrastructure, the adaptive model doesn’t require abandoning that investment. It extends it by providing the connectivity, context, and runtime delivery capabilities that centralized stores were never designed to provide. The centralized store continues to serve its reporting and analytics workloads. The adaptive data layer handles the requirements that AI imposes (real-time context, cross-system reasoning, and governed access at the point of decision).
How to measure AI data readiness
Traditional data management metrics tell you whether the infrastructure is running. They don’t tell you whether the data is actually ready for AI. The distinction matters because an AI system can operate on technically available data and still produce outputs that are incorrect, incomplete, or misaligned with business objectives. Let’s take a look at the KPIs your team should be measuring:
Data-to-model readiness measures how quickly a new AI use case can go from concept to production with the data it needs. This is the metric that reveals whether the data foundation is enabling AI or blocking it. Organizations with adaptive data models can typically deliver new use cases in days or weeks. Organizations dependent on centralization projects measure this timeline in months. The gap represents direct business value deferred.
Data reuse rate tracks how many AI use cases share connected data sources, models, and governance policies. A rising reuse rate indicates that the data foundation is compounding, delivering more value with each deployment. A low reuse rate signals that every AI project is building its own data pipeline from scratch, which is the architectural pattern most likely to create unsustainable maintenance costs.
Context accuracy measures whether the data delivered to AI systems at runtime actually contains the business semantics needed for correct reasoning. This is not the same as traditional data quality metrics like completeness or consistency. A customer record can be 100% complete and consistent and still lack the operational context an AI agent needs to make a correct decision about that customer. Context accuracy requires ongoing validation by domain experts who understand the business logic that AI is expected to apply.
Governance coverage measures what percentage of AI-accessible data has embedded access controls, lineage tracking, and audit capabilities. In regulated industries, this metric determines whether AI can be deployed at all for workflows involving sensitive data. Gartner forecasts that 60% of organizations will fail to realize expected value from AI by 2027 because their governance is not strong enough. The organizations that track governance coverage are the ones that will scale AI into regulated workflows without creating the exposure that causes projects to be shut down.
Building the foundation for Knowledge Fabric
By delivering federated, queryable, governed data inputs, the adaptive data model creates what Knowledge Fabric needs to operate. Knowledge Fabric builds on the connected data layer, creating a semantically linked, contextualized view that makes AI fluent in an organization's business language. The data foundation handles the mechanics, things like connectivity, organization, governance, and runtime delivery. Knowledge Fabric handles the semantics, things like understanding what terms mean in a specific context, how concepts relate to each other, and how to translate natural language into precise queries across the entire data landscape.
This distinction between mechanics and semantics is critical because it explains why organizations that invest heavily in data infrastructure often still struggle with AI outcomes. The infrastructure can be technically excellent, pipelines running on schedule, data quality scores above threshold, governance policies in place, and AI systems still produce mediocre results because the semantic layer is missing. The data is available but not understood. It is accessible but not meaningful. Bridging that gap is what transforms production AI from a technical capability into a business capability.
Choosing a platform that adapts
The vendor landscape for AI data management is undergoing rapid consolidation and repositioning. Every data warehouse, integration platform, and governance tool has added "AI-ready" to its marketing. The result is a market where fundamentally different architectural approaches are described in identical language.
Think about the evaluation criteria we’ve already discussed so you can cut through the noise. First, assess whether the platform requires data centralization as a prerequisite or can connect to data as is in place. If the platform requires consolidation before AI can operate, the time-to-value equation will follow the pattern that has already produced industry-wide abandonment rates above 40%.
Second, evaluate how the platform handles business context. A system that can only access what appears in a prompt or a static knowledge base will not handle the variability that makes enterprise workflows difficult. The platform should be able to organize and serve context specific to each AI use case, and it should improve as it accumulates operational feedback over time.
Third, examine the governance model. For any workflow that touches regulated processes, financial data, or customer information, you need permission-aware access that inherits from source systems rather than requiring a parallel governance infrastructure. If you cannot explain a decision to a regulator or an internal auditor, the system is not ready for workflows that matter.
Fourth, look at deployment timelines honestly. If a vendor describes production deployment as a 6-12 month engagement it’s a no-go. Managed AI delivery platforms that have gained traction in the enterprise market are delivering production-ready AI in days or weeks by assembling proven, modular components into configurations tailored to each use case rather than building custom solutions from scratch.
The organizations that will capture the most value from AI data management in 2026 and beyond are the ones that stop treating data preparation as a project that must be completed before AI can begin. The data foundation and the AI applications should evolve together, each informing the other, each making the other more effective. The technology is ready. The architectural patterns are proven. The question is whether your organization is ready to stop centralizing and start connecting.
Unframe is a managed AI delivery platform with AI-native data management built in; every solution runs directly on your data, from wherever it is, with zero manual prep.
To learn how Unframe is simplifying AI data management for our enterprise customers, visit our page on the topic and discover how we can help you.






.svg)